ベクトル検索時代のSEO戦略|Google意味理解の進化に適応せよ

序章:キーワードの時代は終わったのか?
「狙ったキーワードをコンテンツに散りばめているのに、一向に順位が上がらない」「ユーザーの意図を汲み取ったはずの記事が、なぜか評価されない」
もしあなたがこのような壁に突き当たっているとしたら、それはあなたの努力が足りないからではありません。その原因は、私たちが慣れ親しんだ検索の世界で、静かでありながら根本的な地殻変動が起きているからです。
Google検索は、もはや単語と単語を照合するだけの単純な辞書ではなくなりました。それは、言葉の裏にある「意味」や「文脈」、さらにはユーザーの隠れた「意図」までをも理解しようとする、高度なAIへと進化を遂げたのです。
この記事では、その進化の核となる「ベクトル検索」という技術を徹底的に解き明かします。なぜGoogleは意味を理解できるようになったのか。その技術は私たちのSEO戦略にどのような変革を迫るのか。そして、私たちはこの新しい時代にどう適応していけば良いのか。
本稿は、AI時代の荒波を航海するための羅針盤です。読み終える頃には、あなたは変化の正体を理解し、未来の検索エンジンと向き合うための確かな戦略を手に入れているはずです。
第1章:Google検索「意味理解」進化の歴史
現在のベクトル検索の重要性を理解するためには、Googleがいかにして「意味」を理解するに至ったか、その進化の道のりを辿る必要があります。単純なキーワードマッチングから、文脈を捉えるAIへと変貌を遂げたアルゴリズムの歴史は、そのまま現代SEO戦略の前提知識となります。このテーマの全体像については、【2026年版SEO未来予測】で体系的に解説しています。
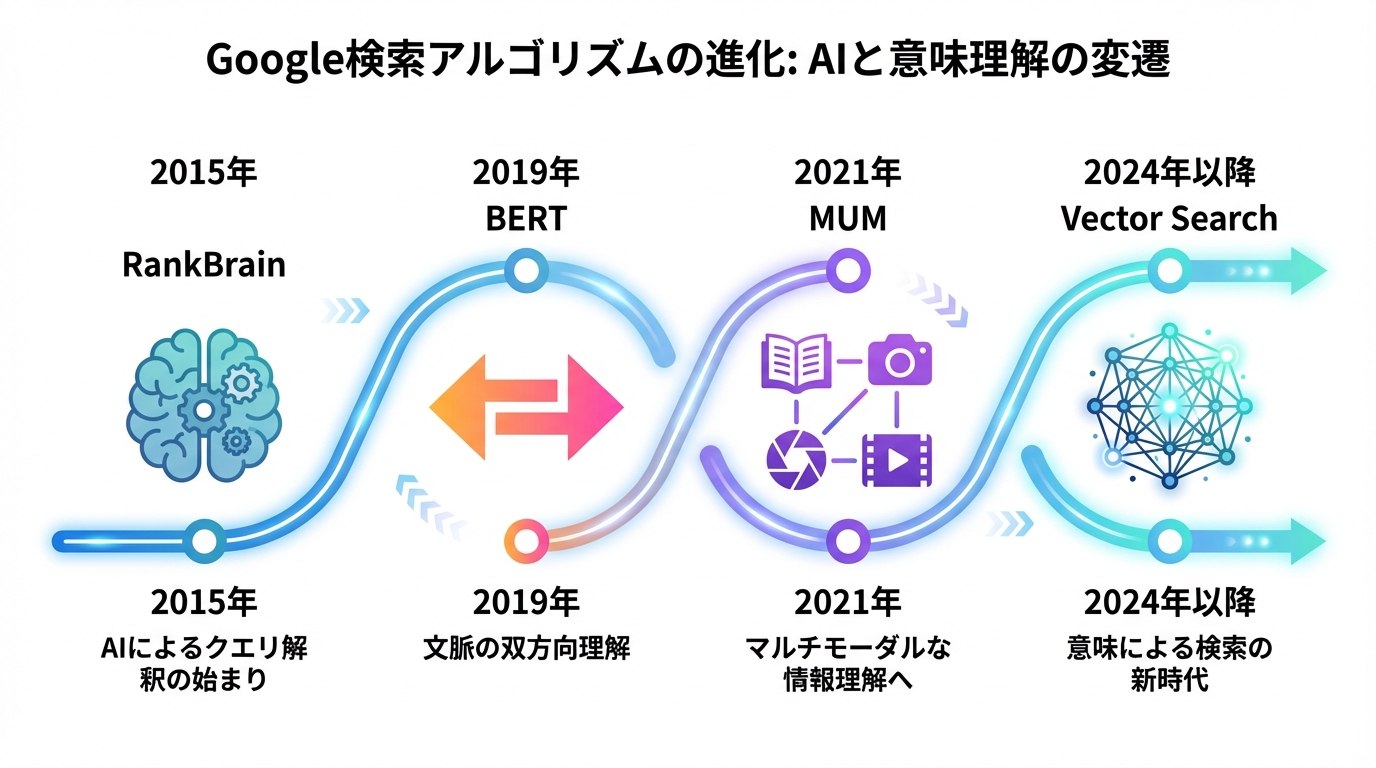
転換点のはじまり:RankBrainと会話型検索への対応
Googleの検索アルゴリズムにAIが本格的に関与し始めた最初の狼煙、それが2015年に導入された「RankBrain」です。それまでのアルゴリズムは、過去のデータに基づき人間が定義したルールで動いていました。しかし、日々生まれる膨大な数の未知の検索クエリ(全検索の約15%)や、「OK, Google」に代表されるような曖昧な会話型の質問には、既存のルールだけでは対応しきれなくなっていました。
RankBrainは、この課題を解決するために導入された機械学習システムです。単語そのものではなく、単語やフレーズが持つ「概念」をベクトルとして捉え、未知のクエリであっても、意味的に近い既知のクエリに変換して最適な検索結果を推測します。これは、Googleがキーワードの文字列一致という呪縛から逃れ、ユーザーの「意図」という本質に迫るための、壮大な試みの第一歩でした。この思想こそが、後のBERTやベクトル検索へと続く道筋をつけたのです。
革命的進化:BERTアップデートと「文脈」の双方向理解
検索の歴史における大きな転換点の一つが、2019年に発表された「BERT(Bidirectional Encoder Representations from Transformers)」アップデートです。BERTが注目されたのは、文中の単語を前後の文脈との関係で捉え、検索クエリの意図理解を大きく改善した点にあります。
それ以前のモデルは、文章を左から右へ、あるいは右から左へと一方通行でしか処理できませんでした。そのため、「銀行の口座」と「銀行の土手」のように、同じ単語でも文脈によって意味が全く異なるケースの判別が苦手でした。
しかし、BERTは文章中のある単語の意味を理解するために、その単語の前後の単語すべてを同時に考慮します。例えば、「ブラジルから日本への旅行者」というクエリにおいて、「への」という助詞が持つ方向性の意味を正確に捉え、「日本からブラジルへ」という逆の意味のページを除外できるようになりました。これにより、検索エンジンは単語の集合体ではなく、人間が話すような自然な文章のニュアンスを、かつてない精度で理解できるようになったのです。この進化は、単なるAIによる記事作成のレベルを超え、検索品質そのものを根底から引き上げました。
次世代への拡張:MUMとMUVERAが目指す未来
BERTの成功は、ゴールではなく新たな始まりでした。Googleは次なるステップとして、さらに高度なAIモデルの開発を進めています。その代表格が「MUM(Multitask Unified Model)」と「MUVERA」です。
2021年に発表されたMUMは、BERTの1,000倍もの性能を持つとされ、その最大の特徴は「マルチモーダル」な理解力にあります。テキスト情報だけでなく、画像、音声、動画といった異なる形式の情報を横断的に理解し、より複雑で多角的な問いに答えようとします。例えば、「富士山の写真を撮ったけど、次は阿蘇山に登りたい。何か準備で違うことはある?」といった、複数の意図が入り混じった質問にも、テキストと画像を統合的に解釈して回答を生成する未来を目指しています。
一方、MUVERAは、複数ベクトル(マルチベクトル)で表現された文書・クエリの検索(multi-vector retrieval)を、現実的な計算コストで高速に実行するためのアルゴリズムです。膨大な情報をベクトル化し、類似性を計算するプロセスは非常に負荷が高いため、これを効率化するMUVERAのような技術がなければ、MUMのような高度な検索体験は実現できません。
これらはまだ発展途上の技術ですが、Googleが目指す「究極の検索」—すなわち、あらゆる形式の情報をシームレスに理解し、ユーザーが尋ねる前にさえ答えを提示する—という壮大なビジョンの方向性を示しています。この未来を見据えることが、これからのSEO戦略を考える上で不可欠なのです。
第2章:ベクトル検索とは何か?その仕組みとSEOへの影響
Googleの意味理解アルゴリズムの心臓部、それが「ベクトル検索(セマンティック検索)」です。この技術の仕組みを理解することは、現代のSEOを理解することと同義と言えます。ここでは、その技術的な骨子から、私たちのSEO戦略に与える具体的な影響までを、深く、しかし分かりやすく解説していきます。
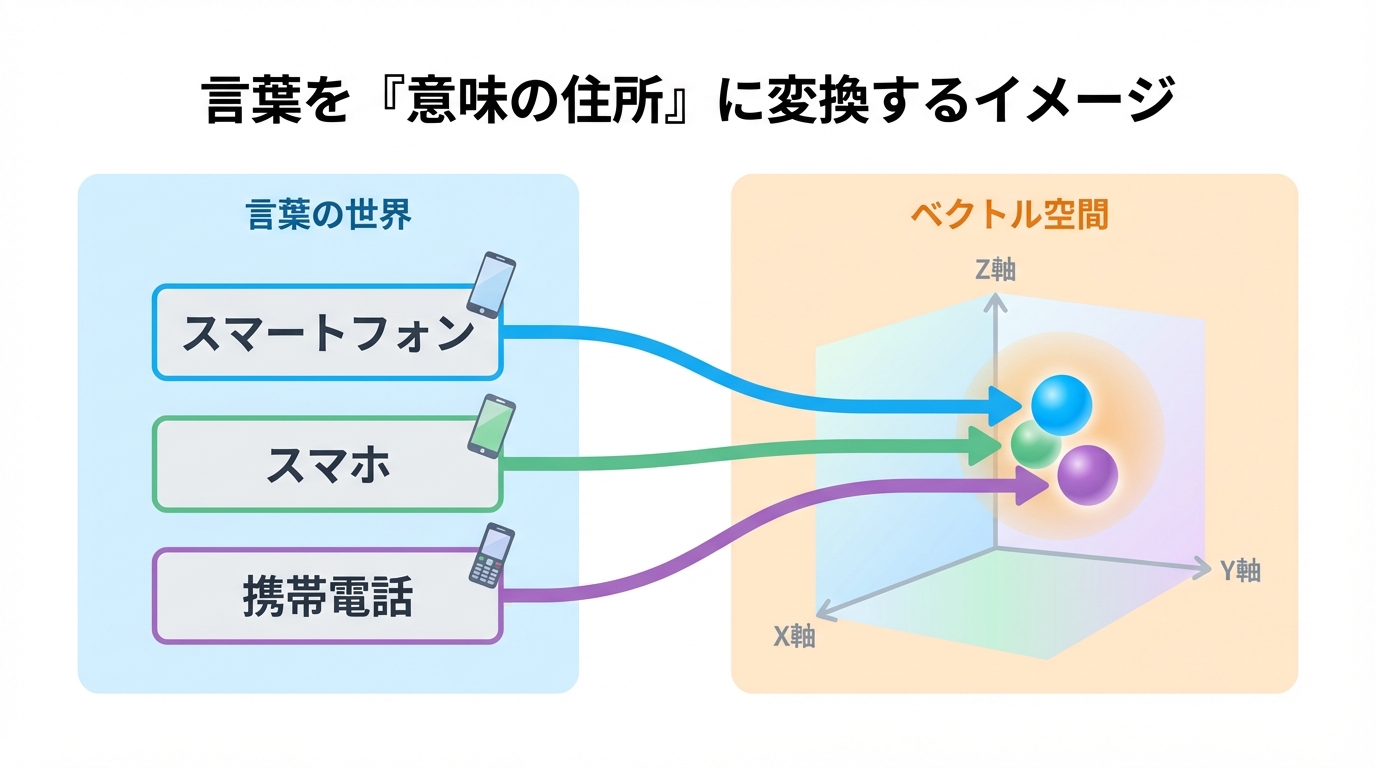
言葉を「住所」に変換する技術:エンベディングの基本
ベクトル検索を理解する上で、最初の鍵となるのが「エンベディング(Embedding)」という概念です。これは、一言で言えば「言葉や文章を、AIが計算できる数値の列(ベクトル)に変換する技術」です。
コンピュータは「SEO」や「検索エンジン最適化」といった単語そのものを直接理解することはできません。そこで、これらの言葉が持つ意味や文脈を、多次元空間上の特定の「座標」として表現します。この座標こそがベクトルであり、私たちはこれを「言葉の住所」と考えると直感的に理解しやすいでしょう。
このベクトル空間では、不思議なことに、意味が近い言葉同士は物理的に「ご近所さん」になります。例えば、「スマートフォン」という言葉の住所の近くには、「スマホ」「携帯電話」「モバイルデバイス」といった言葉の住所が集まります。このエンベディングという魔法によって、コンピュータは初めて、単なる文字列としてではなく、言葉の「意味」を数学的な距離として扱えるようになるのです。
キーワード一致から「意味の近さ」へ:類似度検索の仕組み
言葉を「住所」に変換できれば、次に行うことはシンプルです。ユーザーが検索窓に入力したクエリ(質問)も同じようにエンベディングし、その「住所」と、Web上に存在する無数のコンテンツの「住所」との距離を計算します。そして、最も距離が近い、つまり「ご近所さん」であるコンテンツから順に表示する。これがベクトル検索の核心である「類似度検索」の仕組みです。
従来のキーワード検索が、コンテンツ内に検索キーワードという「文字列が完全に一致するか」を厳格に見ていたのに対し、ベクトル検索は「意味の住所がどれだけ近いか」を見ています。この根本的な変化こそが、「スマホ」と検索した時に、本文中に「スマホ」という単語が一度も登場しなくても、「携帯電話の選び方」といった記事が上位に表示される理由を論理的に説明します。
このシフトは、私たちマーケターに、検索エンジンの評価基準が根本から変わったという事実を突きつけます。もはや、単語の表面をなぞるだけでは不十分なのです。より深いレベルでの「意味」の繋がりを意識したAI時代の内部リンク戦略が求められています。
SEO戦略の再定義:ベクトル検索がもたらす5つの変化
キーワードを詰め込むSEOはずいぶん前に終わりを迎え、これからは「文脈」の一致が重要となります。私たちが開発したOGAIのリンク探索エンジンがベクトル検索ベースなのは、Googleの進化に合わせているためです。「言葉の住所」を合わせたリンク設置をすること、それが次世代のSEO対策では重要となります。Googleのアルゴリズムを正しく推測し、いち早くSEO対策に組み込んでいかないと、特にYMYL領域でのSEOは後手を踏むことになりかねません。
私たちは消費者行動レポートの段階から次世代のSEOを予測し、常に5年先のSEO対策を見据えて行動しています。今はメッシー・ミドル時代のSEOの終盤期です。OGAIは次の消費者行動モデルを予想し、その結果Googleがどういう形でユーザーの価値を高めようとしているのかをいち早く予測し、先んじたSEO対策を組み込む計画としています。ベクトル検索の普及は、具体的に以下の5つの変化をSEO戦略にもたらします。
- ロングテール戦略の変質
従来は検索ボリュームが少なくてもコンバージョン率の高いニッチなキーワードを狙うのが定石でした。しかし今後は、より曖昧で会話的な、これまで誰も検索しなかったような「超」ロングテールな質問に対しても、意味を理解したAIが適切なページを見つけ出します。つまり、ユーザーの具体的な悩みにピンポイントで答えるコンテンツの価値が飛躍的に高まります。 - トピックの網羅性の重要度UP
あるテーマについて解説する際、関連するサブトピックや周辺知識をどれだけ網羅的に含んでいるかが、ページの専門性を示す重要なシグナルとなります。ベクトル検索は、コンテンツ全体の意味的な広がりと深さを評価するため、トピッククラスター戦略のように、体系的に情報を整理することがこれまで以上に重要になります。 - 多言語・マルチモーダルSEOの台頭
MUMが示すように、Googleは言語やコンテンツ形式の壁を越えようとしています。将来的には、日本語のページが海外の検索ユーザーに評価されたり、動画コンテンツがテキストクエリの最適な回答として提示されたりする場面が増えるでしょう。コンテンツ戦略をテキストだけに限定しない視点が求められます。 - E-E-A-Tの文脈的評価
E-E-A-T(経験、専門性、権威性、信頼性)の評価も、より文脈的に行われるようになります。単に権威あるサイトからリンクが張られているかだけでなく、そのサイトがどのような文脈であなたのコンテンツに言及しているか、その「意味」までが評価対象となり得ます。 - 内部リンク構造の再考
キーワードをアンカーテキストに含めるだけの内部リンクは過去のものとなります。今後は、ページAとページBが「意味的にどれだけ近いか」がリンクの価値を決定します。サイト全体が意味的なネットワークとして緊密に連携している構造が、クローラビリティとサイト評価の両方を高めます。
第3章:セマンティック検索の実装における技術的課題と解決策
理想的なセマンティック検索は強力ですが、その実装は決して平坦な道のりではありません。この章では、競合サイトがほとんど触れることのない「現実の壁」、すなわち技術的な課題に踏み込みます。この課題を理解することは、Googleが日々どのような問題と格闘しているかを想像する手助けとなり、より本質的なSEO思考を養うことに繋がるでしょう。
課題1:エンベディングモデルの品質と専門性
セマンティック検索の精度は、すべての土台となるエンベディングモデルの品質に根本的に依存します。一般的なWebテキストで学習された汎用的なモデルは、日常的な会話や一般的なトピックについては高い性能を発揮します。しかし、医療、法律、金融、あるいは特定の製造業といった専門領域では、業界特有の用語や、同じ単語でも文脈によって全く異なる意味を持つニュアンスを正確にベクトル化できないケースが少なくありません。
例えば、法律分野における「善意」は、日常会話で使われる「親切心」とは全く異なる「ある事実を知らないこと」を意味します。汎用モデルがこの違いを理解できなければ、検索結果の品質は著しく低下します。
この解決策として、特定の専門ドメインの大量の文献データでモデルを追加学習させる「ファインチューニング」や、そもそも特定の用途に特化して設計されたモデル(例:Amazon Titan Text Embeddings)を利用するアプローチが考えられます。単一の万能モデルに頼るのではなく、目的に応じて最適なモデルを選択・組み合わせる柔軟な思考が求められるのです。
参照:Amazon Titan Text Embeddings models – Amazon Bedrock
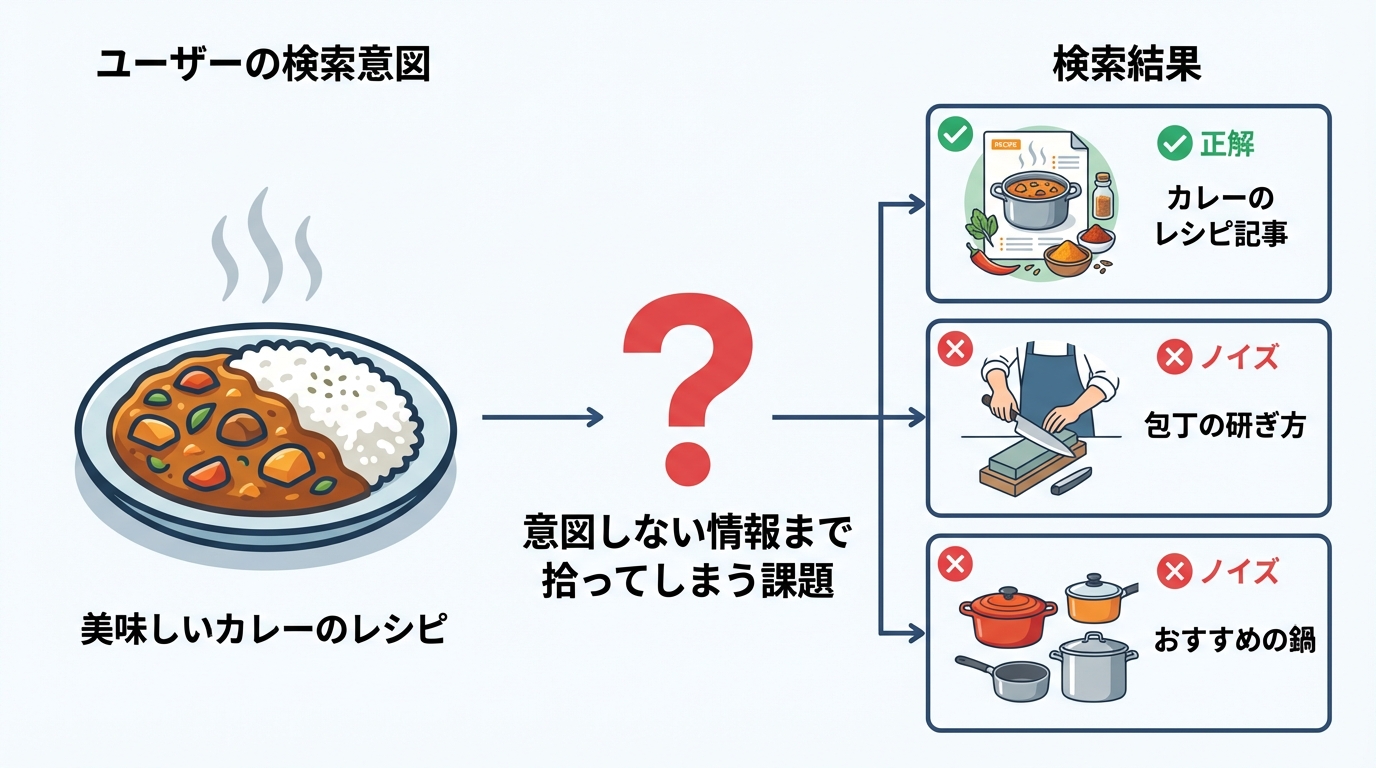
課題2:検索ノイズと精度のトレードオフ
セマンティック検索は、意味的に近いものを幅広く拾えるという利点を持つ反面、意図しない関連性の低い情報、いわゆる「ノイズ」まで検索結果に含んでしまうという特有の課題を抱えています。
例えば、「美味しいカレーのレシピ」で検索した際に、レシピ記事の中に「玉ねぎを上手に切るには、よく切れる包丁が欠かせません」という一文があったとします。セマンティック検索は「包丁」という単語の関連性から、「包丁の研ぎ方」や「おすすめの包丁ブランド」といった、ユーザーが全く意図していないページまで結果に含めてしまう可能性があります。これは、意味の近さだけを追求することの副作用です。
このノイズをいかに制御するかが、実用化における最大の鍵となります。解決アプローチとしては、キーワード検索とベクトル検索を組み合わせた「ハイブリッド検索」が有効です。まずキーワードで候補を絞り込み、その中でベクトル検索によって意味的に最適なものを順位付けする方法です。他にも、AIのハルシネーション対策で用いられるRAG(Retrieval-Augmented Generation)技術のように、一度ベクトル検索で取得した結果を大規模言語モデル(LLM)で再度フィルタリングし、文脈との整合性を検証する手法や、類似度の閾値を調整するといったチューニングが考えられます。
課題3:コストとパフォーマンスの両立
大規模なデータセット(例えば、数百万ページ規模のWebサイト)に対して、高精度なベクトル検索を低遅延で実行するには、相応の計算コストと高度なインフラが必要です。特に、ユーザーからの検索リクエストがあるたびに、すべてのデータとの類似度を総当たりで計算するのは現実的ではありません。
この課題を解決するため、近年では「ベクトルデータベース」と呼ばれる専用のデータベースが注目されています。これは、事前にベクトル間の近傍関係を効率的に検索できるような特殊なインデックス(例:HNSW)を構築しておくことで、検索速度を飛躍的に向上させる技術です。
しかし、専用データベースの導入・運用には専門的な知識と追加のコストがかかります。そのため、企業の規模や要件によっては、ベクトルデータベースを導入せず、オープンソースのライブラリ(例:NumPy, Faiss)を活用して、コストを抑えながら十分なパフォーマンスを実現するアーキテクチャを選択する場合もあります。絶対的な正解はなく、精度、速度、コストのバランスをいかに最適化するかが、技術者の腕の見せ所となるのです。
第4章:AI時代の実践的SEO戦略「AIO」へのシフト
ここまで見てきた歴史的背景と技術的理解を踏まえ、これからのマーケターが取り組むべき具体的なアクションプランを提示します。もはや従来のSEO(Search Engine Optimization)という枠組みだけでは不十分です。私たちはその概念を拡張し、「AIO(AI Optimization)」、すなわち「AIに対する最適化」へとシフトする必要があります。
AI Overview時代の現実:ゼロクリック検索とどう向き合うか
Google検索結果の最上部にAIによる要約が表示される「AI Overviews」(旧SGE)は、私たちのビジネスに大きな影響を及ぼします。多くの調査で、AI Overviewsの登場により、従来のオーガニック検索結果へのクリック率が大幅に低下する可能性が指摘されています。ユーザーは、サイトを訪れることなくAIの回答だけで満足し、検索行動を終えてしまう「ゼロクリック検索」が増加するのです。
しかし、これを単なる脅威と捉えるのは早計です。視点を変えれば、これは新たな機会でもあります。AIの回答に自社のコンテンツが「引用元」として表示されることは、これ以上ない強力なブランディングとなります。それは、AI Overviewsの表示上で「参考リンク(情報源)」として露出が増え、結果としてそのトピックでの信頼性認知につながる可能性があるためです。
これからの時代、私たちが追うべき指標は、単純なトラフィックの「量」から、ブランド認知や権威性といった「質」へと変化していきます。AIに引用されることで得られる質の高いトラフィックや、たとえクリックされなくてもユーザーに信頼感を醸成できるという価値を、正しく評価する視点が必要不可欠です。この変化に適応できなければ、SGE時代のSEO戦略で生き残ることは難しいでしょう。
AIに引用されるコンテンツの条件:AIOの実践
では、どうすればAIに「回答の情報源」として選ばれるのでしょうか。そのための具体的な戦術がAIO(AI Optimization)です。これは従来のSEOと全く異なるものではなく、その延長線上にありながら、より「AIによる抽出のしやすさ」を意識したアプローチと言えます。GoogleもAI機能に関するウェブサイト向けの情報を公開しており、その重要性は増すばかりです。
AIOの基本原則は以下の通りです。
- 結論ファーストで明確な答えを提示する
ユーザーの質問(クエリ)に対して、記事の冒頭で簡潔かつ明確な答えを提示します。AIは、このような直接的な回答を要約の材料として抽出しやすい傾向があります。 - 情報を構造化する
Q&A形式(「〜とは?」)、番号付きリスト、箇条書きなどを活用して情報を整理します。これにより、AIがコンテンツの構造を理解し、特定の要素を抜き出しやすくなります。 - 一次情報と信頼できるデータで裏付ける
独自の調査データ、専門家としての実体験、公的機関の統計など、他のサイトにはない一次情報で主張を裏付けます。これは、AIがコンテンツの信頼性を判断する上で極めて重要なシグナルとなります。単なる情報の要約ではなく、AI記事に信頼性を付加するE-E-A-Tの観点が不可欠です。 - 構造化データを実装する
特にFAQ(よくある質問)に関する情報を「FAQPageスキーマ」を用いてマークアップすることは、AIがQ&Aのペアを正確に認識する手助けとなり、AI Overviewでの引用に繋がる可能性を高めます。
サイト構造の進化:セマンティック・メッシュ・バイパスモデルへ
AIが個々のコンテンツだけでなく、コンテンツ間の「意味的な繋がり」まで理解する時代において、サイトの内部リンク構造もまた、抜本的な進化を遂げるべきです。これまで有効とされてきたトピッククラスターモデルも、コンテンツが爆発的に増加するAI時代においては、管理の破綻という構造的限界に直面しつつあります。
そこで私たちが提唱するのが、次世代のサイト構造設計『セマンティック・メッシュ・バイパスモデル』です。これは、AIがコンテンツの意味を理解し、網の目のように自律的に関連ページを繋ぐ「セマンティック・メッシュ」と、人間がビジネスゴールに基づき戦略的な動線を確保する「戦略的バイパス」を融合させたハイブリッドなモデルです。
AIが構築するメッシュ構造は、サイト内のあらゆるページへの経路を最短化し、これまで評価が届きにくかったロングテール記事群にも効率的に内部リンクの価値を分配します。これにより、サイト全体の専門性が有機的に強化され、Googleに対して強力なシグナルを送ることが可能になります。より具体的な手順については、AI時代の新サイト設計論『セマンティック・メッシュ・バイパスモデル』の全貌をご覧ください。
結論:意味を制する者が、これからの検索を制する
RankBrainからBERT、そしてベクトル検索へ。Googleのアルゴリズム進化の歴史は、一貫して「ユーザーの意図を、より深く、より正確に理解する」という目的に向かって進んできました。ベクトル検索は、その目的を達成するための強力な手段に他なりません。
この大きな変化の潮流の中で、小手先のキーワード戦術やテクニックは、もはやその効力を失いつつあります。これからの検索の世界で評価されるのは、ただ一つ。ユーザーが本当に知りたいことは何かを徹底的に考え抜き、その問いに対して、専門性と信頼性、そして独自の経験に裏打ちされた「本質的な価値」を提供し続けることです。
AIの進化は、決して脅威ではありません。むしろ、真に価値あるコンテンツが正当に評価される時代の到来を告げるものです。この変化を恐れるのではなく、新たな機会と捉え、ユーザーと真摯に向き合うこと。それこそが、アルゴリズムの変動に決して揺らぐことのない、最も普遍的で強力なSEO戦略なのです。
意味を制する者が、これからの検索を制します。さあ、新しい時代の扉を開きましょう。