AIの嘘(ハルシネーション)を防ぐRAGとGroundingとは?

専門家が語るAIの罠:その判例、本当に実在しますか?
生成AIが提示した「最高裁判所の判例」を、そのままクライアント向けの解説記事に掲載しようとした矢先、念のために事件番号を検索したところ、それが全くの架空の事件だった――。これは、実際に私が体験した出来事です。
もし、あのまま公開していたら、専門家としての信頼は失墜し、最悪の場合、懲戒処分を受けていたかもしれません。この体験以来、私は「AIの知識」を安易に信用することを完全にやめました。AIは、その構造上、いとも簡単に、そして悪びれることなく「もっともらしい嘘」をつきます。この現象はハルシネーションと呼ばれ、情報の正確性が業務の根幹をなす私たち専門家にとって、まさに業務上の「地雷」と言えるでしょう。
AIの回答には必ずリアルタイム検索で裏付けを取り、ソースURLを提示させる。「疑う機能」が標準搭載されていないAIツールは、専門家の実務では極めて危険なツールでしかありません。
しかし、「AIは嘘をつくから一切使わない」と結論づけるのは、あまりにも早計です。もし、AIに嘘をつかせないとまでは言えなくとも、嘘をつく確率を大幅に低減する技術が存在するとしたらどうでしょうか。
本記事では、AI開発の専門家として、そしてSEOとE-E-A-Tを深く理解する立場から、AIのハルシネーションを根本から防ぐための技術「RAG(Retrieval-Augmented Generation)」と、その思想的背景にある「Grounding(グラウンディング)」について、その仕組みから法務リスク、実務への導入方法までを体系的に解説します。AIに対する漠然とした不信感を、技術的根拠に基づいた確信へと変えるための知識がここにあります。
なぜAIは平然と嘘をつくのか?ハルシネーションの正体
AIが生成するハルシネーションは、決してシステムの「バグ」や「故障」ではありません。むしろ、現在の生成AIの根幹をなす大規模言語モデル(LLM)が持つ、構造的な特性に起因する現象です。この根本原因を理解することが、適切な対策を講じるための第一歩となります。
AIは「真実」を知らない、確率で文章を作る思考プロセス
まず理解すべき最も重要な点は、AIは人間のように「意味」や「真実」を理解しているわけではない、ということです。AIの頭脳であるLLMは、インターネット上の膨大なテキストデータを学習し、「ある単語の次には、どの単語が来る確率が最も高いか」という統計的なパターンを記憶しています。
例えば、「日本の首都は」という文章が与えられた場合、LLMは学習データの中から「東京」という単語が続く確率が極めて高いことを知っているため、「東京です」と回答します。これは、AIが「日本の首都が東京である」という事実を知識として認識しているからではなく、単に確率的に最も「それらしい」単語を予測して繋げているに過ぎません。
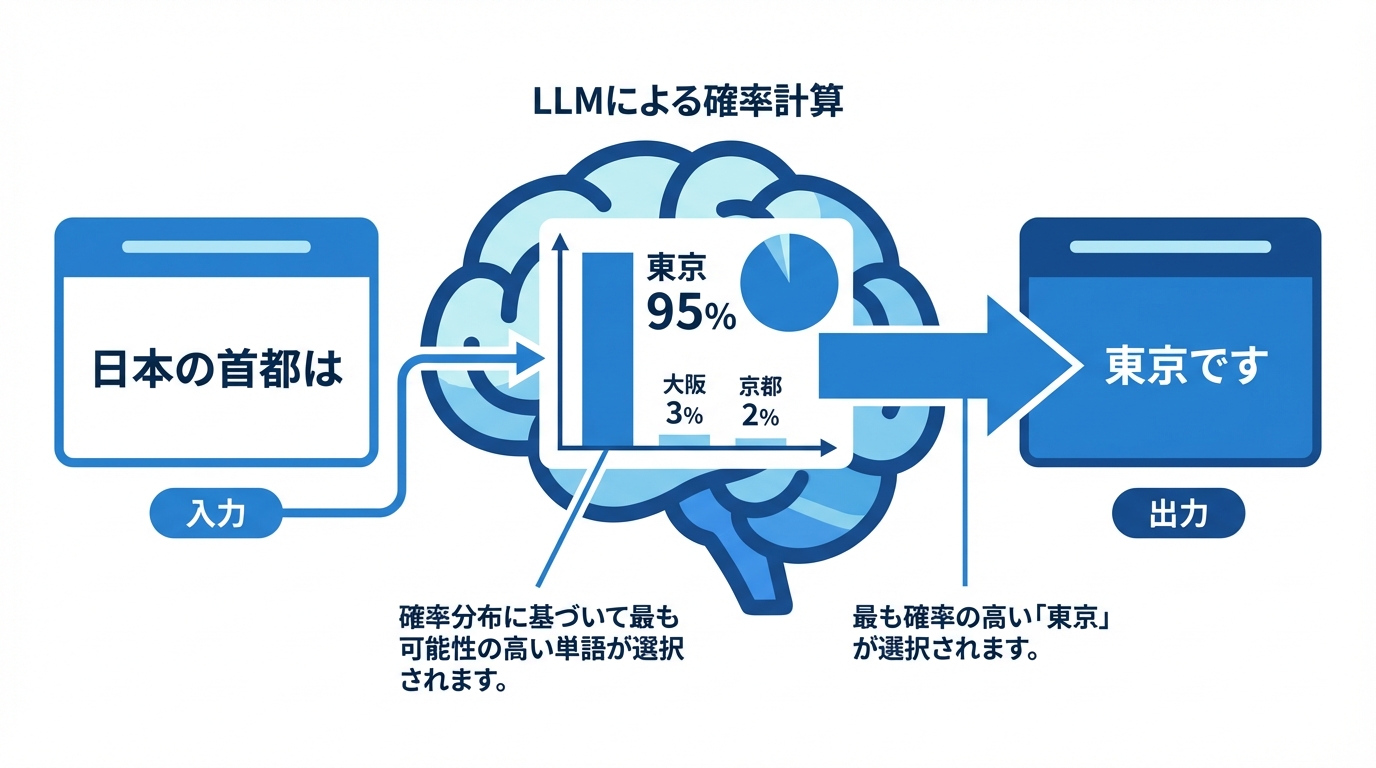
この確率に基づいた文章生成プロセスこそが、ハルシネーションの源泉です。学習データに存在しない情報や、相反する情報が混在している場合、AIは文法的に正しく、非常に流暢でありながらも、事実とは全く異なる「もっともらしい文章」を創造してしまうのです。AIにとって、それは「嘘」ではなく、あくまで確率計算に基づいた「最も自然な出力結果」でしかありません。
プロンプトエンジニアリングだけでは防げない構造的限界
「指示(プロンプト)の出し方を工夫すれば、ハルシネーションは防げる」という考え方があります。確かに、「あなたは誠実な法律アシスタントです」「必ず事実に基づいて回答してください」といった指示を与えるプロンプトエンジニアリングは、回答の精度を高める上で一定の効果があります。
しかし、このアプローチには構造的な限界が存在します。なぜなら、AIは自身の学習データ(内部知識)に存在しない情報については、どれだけ優れたプロンプトを与えられても答えることができないからです。例えば、昨日成立したばかりの法改正の内容や、特定の企業内でのみ共有されている判例研究のデータについて質問しても、AIはそれを「知らない」ため、学習済みの古い情報や関連性の高い単語を組み合わせて、推測で回答を生成しようとします。これが、専門業務において最も危険なハルシネーションを引き起こす典型的なパターンです。
つまり、小手先のテクニックでAIを「正直者」にしようと試みても、その知識の範囲外の問いに対しては無力なのです。根本的な解決には、AIの思考プロセスそのものに外部から介入する、全く新しいアプローチが必要となります。
また、AIの癖を知ることも必要です。AIはユーザーが納得することこそが優良体験だと認識する癖があります。それが嘘の回答だったとしても、ユーザーが納得するのであれば、満足しているという理屈です。これがある限り、ハルシネーションはなくなりません。2026年2月現在において、どれだけこの考えを抑制するようなプロンプトを組み込んだとしても、ハルシネーションはなくなりません。もうしばらくの間は、ハルシネーションとうまく付き合っていく必要があるでしょう。
Grounding:AIに「性悪説」を適用するための重要なアプローチ
AIのハルシネーションに対する本質的な解決策、それが「Grounding(グラウンディング)」という概念です。これは日本語で「接地」「根拠付け」と訳され、その名の通り、AIの回答を、信頼できる特定の情報源(データソース)に強制的に接地させる技術思想を指します。
Groundingの根底にあるのは、「AIは構造的に嘘をつく可能性がある」という、いわばAIに対する「性悪説」です。AIが学習データだけを頼りに自由に推測し、文章を生成することを許可するのではなく、私たちが事前に指定した「信頼できる情報源」という名の檻(おり)の中にAIを閉じ込め、その範囲内でのみ回答を生成させる。これがGroundingの核心です。
このアプローチにより、AIは自身の曖昧な内部知識に頼るのではなく、常に外部の明確な「事実」を根拠(Ground Truth)として回答を生成するようになります。このアプローチにより、専門家が最も懸念する「もっともらしい嘘」が生まれる余地を、アーキテクチャレベルで小さくすることが期待できます。これまで「信頼できない語り部」であったAIを、より「検証可能なツール」として捉え直すための、有力な選択肢の一つと言えるでしょう。
参照:Google Cloud公式:Google検索によるグラウンディング(Vertex AI)
Groundingを実現するRAG(検索拡張生成)の技術的仕組み
前章で述べた「Grounding」という思想を、具体的な技術として実現するのが「RAG(Retrieval-Augmented Generation)」です。日本語では「検索拡張生成」と訳されます。RAGは、大規模言語モデル(LLM)の能力を、外部の信頼できる知識ソースと動的に組み合わせるためのフレームワークです。
RAGのプロセスは、大きく分けて以下の3つのステップで構成されています。
- 検索(Retrieval)
ユーザーからの質問(クエリ)を受け取ると、システムはまずLLMに直接回答を尋ねるのではなく、事前に用意された信頼性の高いデータソース(例:判例データベース、社内マニュアル、官公庁のウェブサイトなど)に対して検索を実行します。この際、質問内容と意味的に関連性の高い情報を効率的に見つけ出すために、ベクトル検索と埋め込み表現などの技術が活用されます。 - 拡張(Augmented)
次に、検索ステップで得られた関連情報を、元のユーザーの質問と組み合わせ、LLMへの新しいプロンプトとして「拡張」します。具体的には、「以下の『参考情報』だけを根拠として、〇〇という質問に答えてください」といった形式の指示文を生成します。 - 生成(Generation)
最後に、拡張されたプロンプトをLLMに送信します。LLMは、プロンプト内で提供された「参考情報」という明確な根拠(Ground Truth)に基づいて回答を生成します。これにより、LLMは自身の内部知識だけに頼ることなく、指定されたデータソースに基づいた、事実に基づいた回答を出力することができるのです。
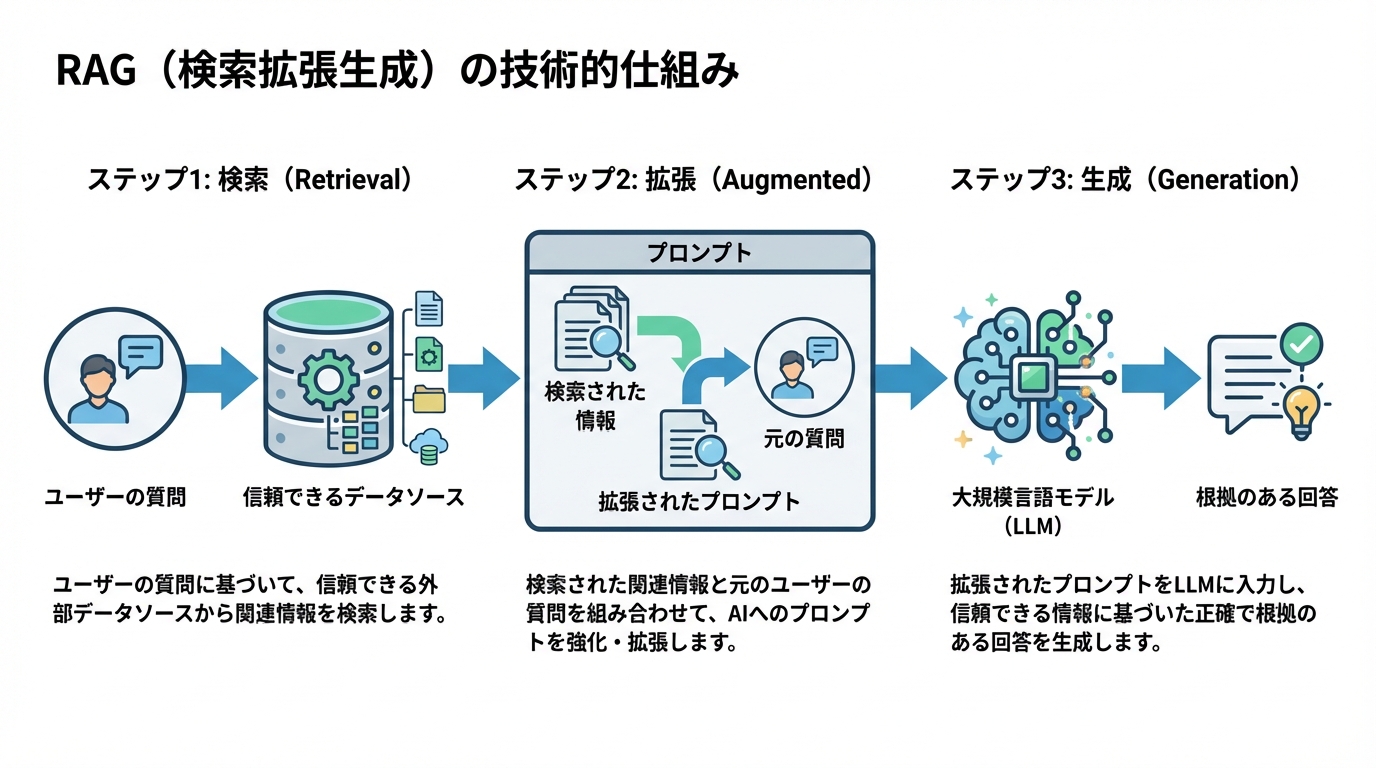
この一連の流れこそが、AIに自由な推測をさせず、常に「事実」を根拠とした回答を生成させるための根幹技術です。RAGを導入することで、AIは単なる文章生成ツールから、信頼性の高い情報源に基づいた回答を生成する、高度なリサーチアシスタントへと進化します。
専門家がRAG導入で直面する「3つの壁」とその越え方
RAGはハルシネーション対策の切り札となり得る技術ですが、その導入は決して平坦な道のりではありません。特に、情報の正確性と機密性が厳しく問われる弁護士や税理士といった専門家が実務で活用する際には、乗り越えるべき3つの大きな壁が存在します。
【第1の壁】データソース選定:何をAIの「六法全書」とするか
RAGシステムの品質は、参照するデータソースの質によって決まります。これは「Garbage In, Garbage Out(ゴミを入れればゴミしか出てこない)」という情報科学の原則そのものです。AIに不正確で古い情報を与えれば、その出力もまた不正確で古いものになります。
したがって、専門家がRAGを導入する上で最も重要なのが、AIの「六法全書」とも言うべき、信頼できるデータソースを厳選することです。選定にあたっては、以下の基準を考慮する必要があります。
- 正確性: 公的機関の発表、査読付き論文、信頼できる判例データベースなど、情報の正確性が担保されていること。
- 最新性: 法改正や最新の判例、通達など、常に情報がアップデートされていること。AIの知識カットオフ問題を回避するためにも不可欠です。
- 網羅性: 業務に必要な情報領域を十分にカバーしていること。
- 著作権: 後述する法務リスクをクリアしている、利用許諾の取れた情報であること。
具体的には、最高裁判所の判例検索システム、e-Gov法令検索、国税庁のウェブサイト、所属する業界団体の公式見解などが候補となるでしょう。これらの信頼できる情報源を体系的に整理し、AIが参照する知識の土台を構築することが、RAG導入成功の第一歩となります。
【第2の壁】法務リスク:著作権と個人情報保護の遵守
RAGのデータソースとして外部のウェブサイトや文献を利用する際には、著作権侵害のリスクが伴います。また、クライアントに関する情報をデータソースに含める場合には、個人情報保護法への配慮が不可欠です。
著作権に関しては、日本の著作権法第30条の4において、情報解析を含む「著作物に表現された思想又は感情の享受を目的としない」利用は、必要と認められる限度で著作権者の許諾なく行える場合がある一方、著作権者の利益を不当に害することとなる場合は適用されないとされています。しかし、AIが生成した文章が、元の著作物の表現に酷似している場合(類似性・依拠性)、著作権侵害と判断されるリスクは依然として残ります。AIによる記事生成における著作権の問題は、専門家として細心の注意を払うべき点です。
また、相談内容やクライアント情報といった機密情報をデータソース化する際は、個人情報保護法を遵守し、適切な匿名化処理やアクセス制御を行うなど、厳格なセキュリティ対策が求められます。オンプレミス環境でのシステム構築や、セキュリティレベルの高いクラウドサービスを選定することが重要です。
参照:文化庁 AIと著作権について
【第3の壁】ファクトチェック:AIの回答を鵜呑みにしない体制構築
RAGを導入したとしても、ハルシネーションのリスクを完全にゼロにすることは困難です。例えば、データソースの解釈を誤ったり、複数の情報を不適切に組み合わせてしまったりする可能性は残ります。したがって、最終的な情報の正確性を担保するのは、AIではなく人間の専門家であるという原則を忘れてはなりません。
実務でRAGを活用するためには、AIの出力を鵜呑みにせず、必ず人間が検証するファクトチェックの体制を構築することが不可欠です。具体的には、以下のようなワークフローが考えられます。
- 出典の明記: AIには、回答の根拠となったデータソースの箇所(ドキュメント名やページ番号など)を必ず明記させる。
- クロスチェック: 重要な論点については、複数のデータソースを参照させ、回答の一貫性を確認する。
- 最終判断: AIが生成したドラフトを元に、最終的には専門家自身の知見と経験に基づいて内容を精査し、加筆修正を行う。
AIをあくまで「極めて優秀なリサーチアシスタント」と位置づけ、その能力を最大限に活用しつつ、最終的な意思決定と品質保証の責任は人間が担う。この協業体制こそが、専門業務におけるAI活用の最適解です。
結論:AIを「無謬の賢者」から「高速リサーチャー」へ
私たち専門家がAIと向き合う上で、最も重要なのはマインドセットの転換です。AIに「完璧で誤りのない答え」を求める「無謬の賢者」として期待するのではなく、「人間が指定した信頼できる情報源の中から、関連情報を超高速で検索・整理・要約してくれるリサーチアシスタント」として再定義すること。この発想の転換こそが、AIを安全かつ効果的に活用するための鍵となります。
今回解説したGroundingという思想、そしてそれを実現するRAGという技術は、まさにこの新しい関係性を築くための基盤です。AIの自由な発想(確率的な予測)を制限し、我々が用意した「事実」というレールの上を走らせる。これにより、ハルシネーションという最大のリスクをコントロール下に置き、AIの持つ圧倒的な情報処理能力の恩恵だけを享受することが可能になります。
AIは、もはや避けて通れる存在ではありません。その構造的なリスクを正しく理解し、RAGのような適切な技術で制御することで、AIは私たちの業務の質と効率を劇的に向上させる、かけがえのないパートナーとなり得ます。この記事が、AIに対する漠然とした不安を払拭し、専門家としてのWeb上での情報発信を加速させる一助となれば幸いです。